Negli ultimi mesi stiamo studiando approfonditamente una tecnologia che crediamo rivoluzionerà il modo di utilizzare l’intelligenza artificiale con i RAG: la Vettorializzazione e gli Embeddings. Stiamo parlando della tecnologia RAG. In questo articolo andiamo ad approfondire la Vettorializzazione e gli Embeddings nei RAG!
La Vettorializzazione e gli Embeddings nei RAG: Ma cosa è la RAG?
La Retrieval-Augmented Generation (RAG) è una tecnologia che arricchisce l’output dei modelli linguistici di grandi dimensioni (LLM) integrando le informazioni provenienti da una base di conoscenza esterna. Questo processo ha lo scopo di generare risposte più accurate, pertinenti e aggiornate senza la necessità di riaddestrare il modello su nuovi dati. La RAG è paragonabile a un esame con libro aperto, dove il modello, per rispondere a una domanda, prima la comprende, poi cerca le informazioni pertinenti e infine genera una risposta basata su queste informazioni.
I componenti chiave della RAG sono:
- Un motore di ricerca o un sistema di recupero delle informazioni (un database vettoriale), che funge da “indice” per accedere rapidamente a informazioni pertinenti da una knowledge base. Queste informazioni si salvano in questi database grazie alla vettorizzazione.
- Un modello generativo (LLM), che elabora la domanda e, sulla base delle informazioni recuperate, produce una risposta coerente.
Approfondiamo il concetto di vettorizzazione e database vettoriale
La vettorizzazione delle informazioni gioca un ruolo cruciale in questo processo, in quanto è il metodo con cui i dati non strutturati (come testo, immagini e video) vengono convertiti in vettori numerici. Questi vettori rendono possibile il confronto semantico e la ricerca di similarità tra la domanda dell’utente e le informazioni disponibili nella knowledge base. La vettorizzazione trasforma le parole in vettori numerici, dove ogni dimensione del vettore rappresenta un aspetto del significato della parola. Questo consente al motore di ricerca di identificare le informazioni più pertinenti rispetto alla domanda posta.
Esempio:

Vediamo come le parole principe e principessa siano vicine tra di loro, esattamente come re e regina.
Ponendo che la variabile genere possa assumere solo due valori, M e F (usiamo 0 e 1), e che la variabile età possa assumere solo tre valori [Giovane, Mezz’età, Anziano] (usiamo 0, 1, 2), vediamo come degli embedding possano rappresentare queste relazioni:
| Re | [0, 2] |
| Regina | [1, 2] |
| Principe | [0, 1] |
| Principessa | [1, 1] |
Questa rappresentazione riesce a catturare lo status nobiliare di un individuo andando a usare le dimensioni di genere e l’età.
Muovendoci sull’asse delle X possiamo osservare come i due nobili siano equidistanti da una dimensione che rappresenta la differenza di genere (0: maschio, 1: femmina). Muovendoci sull’asse delle Y, invece, possiamo osservare come l’età sia rappresentato dalla distanza dell’embedding dall’asse Y.
In questo esempio abbiamo solo due dimensioni. Di fatto, vengono addestrate delle reti neurali con lo specifico compito di trovare queste rappresentazioni su parecchie dimensioni.
Per mettere in prospettiva, modelli come GPT-3 usano più di 12.000 dimensioni.
Come abbiamo appena visto, le caratteristiche che compongono un vettore possono variare da semplici, come il numero di attori in uno spettacolo teatrale, a complesse, come le texture identificate in un’immagine da una rete neurale, dove il numero 3 può corrispondere alla texture della pelle umana, mentre il numero 10 può corrispondere alla texture del pelo di un gatto. Contrariamente ai modelli di dati tradizionali come il relazionale, dove le query spesso assumono forme come “trova gli ordini di un utente specifico” o “trova i prodotti in vendita”, le query vettoriali di solito cercano vettori simili utilizzando uno o più vettori di query.
Di conseguenza, una gestione efficiente dei dati richiede un sistema di gestione di database dedicato (DBMS), cioè un sistema di archiviazione specializzato progettato per gestire in modo efficiente vettori ad alta dimensione che consentono ricerche rapide di somiglianza tra questi vettori, consentendo il rapido recupero degli elementi più simili da un vasto set di dati.
La Vettorializzazione e gli Embeddings nei RAG: Word Embeddings
Ma come possiamo posizionare centinaia di migliaia di parole in uno spazio in modo che il loro posizionamento corrisponda alle loro proprietà semantiche?
La risposta rapida alla domanda sopra è che gli spazi semantici sono costruiti automaticamente analizzando le co-occorrenze delle parole in grandi corpora di testo. Ma, come le co-occorrenze delle parole possono denotare la similarità semantica? L’idea principale qui è l’ipotesi distribuzionale [Firth, 1957], secondo la quale “a word is characterized by the company it keeps”.
Ad esempio, parole come “Giove” e “Venere” sono considerate simili perché spesso compaiono in contesti simili, come discorsi sul sistema solare o l’astronomia.
La creazione degli spazi semantici avviene principalmente attraverso un processo di apprendimento automatico, noto come apprendimento non supervisionato o auto-supervisionato. Questo metodo non richiede annotazioni manuali dei dati di addestramento, ma si basa sull’analisi di grandi quantità di testo grezzo. Utilizzando questi testi, è possibile calcolare le statistiche sulle co-occorrenze delle parole, che sono fondamentali per determinare le relazioni semantiche tra di esse. Questo processo permette di organizzare le parole in spazi semantici senza bisogno di supervisione esterna o intervento manuale.
Gli “embeddings” delle parole sono una forma speciale di rappresentazione delle parole che sfrutta le reti neurali. Questo tipo di rappresentazione è diventato popolare dopo l’introduzione di Word2vec nel 2013. Gli “embeddings” vengono generati con l’obiettivo di predire parole successive o mancanti in un testo, e sono intrinsecamente collegati alla costruzione degli spazi semantici, poiché catturano le relazioni semantiche tra le parole basate sulle loro co-occorrenze nei testi analizzati.
Langchain: VectorStore e Embeddings per La Vettorializzazione e gli Embeddings nei RAG
Come abbiamo già detto, uno dei modi più comuni per memorizzare e cercare dati non strutturati è quello di incorporarli e memorizzare i vettori di embedding risultanti, e poi al momento della query incorporare la query non strutturata e recuperare i vettori di embedding che sono ‘più simili’ alla query incorporata. Uno store vettoriale si occupa di memorizzare i dati incorporati e di eseguire la ricerca vettoriale per te.
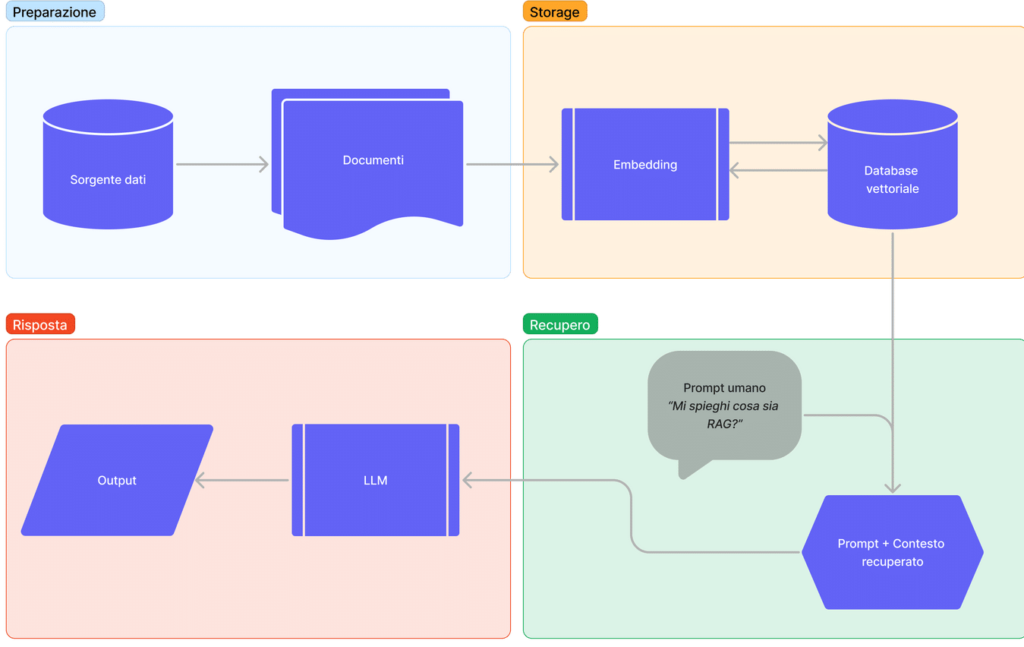
Ora spiegando meglio i vari step:
Il processo di Retrieval-Augmented Generation (RAG) può essere articolato in fasi distinte, ciascuna con un obiettivo specifico per migliorare la qualità e la pertinenza delle risposte fornite da modelli linguistici di grandi dimensioni (LLM). Queste fasi, affinate con le informazioni fornite, delineano un flusso di lavoro dettagliato per integrare dinamicamente una base di conoscenze esterne durante la generazione di una risposta:
Divisione dei Documenti e Preparazione:
- Per superare i limiti di elaborazione degli LLM, i documenti selezionati vengono suddivisi in segmenti minori o “porzioni” utilizzando strumenti come LangChain. Questo consente di presentare al modello solo i frammenti di testo direttamente pertinenti alla query formulata dall’utente.
Vettorizzazione delle Porzioni di Documento:
- Le porzioni di documento vengono trasformate in rappresentazioni numeriche attraverso l’uso di modelli di embedding. Questo processo, noto come vettorizzazione, facilita il confronto semantico dei frammenti di testo convertendo le parole e i concetti in vettori numerici.
Archiviazione nel Database Vettoriale:
- Le rappresentazioni vettoriali ottenute dalla vettorizzazione vengono memorizzate in un database specializzato per il recupero dell’informazione. Questo database consente di effettuare ricerche efficienti basate sulla similarità semantica tra la query e i documenti archiviati.
Recupero dell’Informazione e Augmentation:
- Nella fase di RAG propriamente detta, il database vettoriale identifica e recupera le porzioni di documento più simili e pertinenti alla domanda dell’utente. Queste porzioni selezionate vengono poi combinate con il prompt iniziale per fornire al modello LLM un contesto arricchito.
Generazione della Risposta:
- Infine, l’LLM elabora il prompt arricchito con le informazioni recuperate e genera una risposta. Grazie al contesto aggiuntivo fornito dalle porzioni di documento pertinenti, la risposta del modello sarà più informata, accurata e contestualmente rilevante.
Esempio pratico per la Vettorializzazione e gli Embeddings:
In questo articolo, esploreremo il processo di configurazione di un database ChromaDB, utilizzando gli embedding di OpenAI per vettorializzare una pagina web. Questo approccio ci consente di interrogare la pagina con qualsiasi domanda.
Il codice seguente illustra passo dopo passo come procedere:
from dotenv import load_dotenv
from langchain_community.document_loaders import WebBaseLoader
from langchain.text_splitter import RecursiveCharacterTextSplitter
from langchain_community.vectorstores import Chroma
from langchain_openai import OpenAIEmbeddings, OpenAI
from langchain.chains import RetrievalQA
def main():
load_dotenv()
# Caricamento del testo dallo store di documenti
loader = WebBaseLoader("https://netai.it/")
document = loader.load()
# Suddivisione del documento in frammenti
text_splitter = RecursiveCharacterTextSplitter()
document_chunks = text_splitter.split_documents(document)
embeddings = OpenAIEmbeddings()
# Creazione di un vector store dai frammenti
vectore_store = Chroma.from_documents(document_chunks, embeddings)
qa = RetrievalQA.from_chain_type(
llm=OpenAI(), chain_type="stuff", retriever=vectore_store.as_retriever()
)
query = "Di cosa si occupa l'azienda NetAi?"
result = qa.invoke({"query": query})
print(result)
if __name__ == "__main__":
main()Il codice sopra riportato svolge le seguenti operazioni:
- Carica il testo da una pagina web specifica, in questo caso “https://netai.it/”.
- Divide il documento caricato in porzioni più piccole per facilitarne l’elaborazione.
- Utilizza gli embedding di OpenAI per convertire questi frammenti di testo in vettori numerici.
- Inizializza un database ChromaDB con questi vettori, creando così uno spazio in cui i documenti possono essere facilmente interrogati.
- Permette di eseguire domande specifiche sul contenuto vettorializzato, restituendo le parti più pertinenti del testo come risposta.
Successivamente fornendo una “query” anch’essa verrà vettorializzata e verranno estratti i documenti più rilevanti fornendo così una risposta.
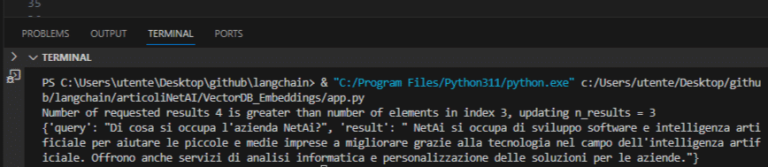
L’output fornito è il seguente:
Successivamente fornendo una “query” anch’essa verrà vettorializzata e verranno estratti i documenti più rilevanti fornendo così una risposta.
L’output fornito è il seguente: