

 Netai")
Introduzione al Naive Bayes Classifier: Un Approccio Intuitivo alla Probabilità Condizionata
Nell’ambito dell’intelligenza artificiale, il Naive Bayes Classifier è un potente strumento basato sulla teoria della probabilità condizionata. Per comprendere meglio il suo funzionamento, esaminiamone un esempio.
Ma perchè un articolo sul Naive Bayes Classifier?
Questo algoritmo è noto per la sua semplicità ed efficienza, rendendolo un punto di partenza ideale per chi si avvicina al machine learning. Il Naive Bayes si basa sul teorema di Bayes, utilizzando la probabilità condizionata per fare previsioni.
È particolarmente utile per problemi di classificazione, come la rilevazione di spam, la categorizzazione di testi e il riconoscimento di immagini.
Nonostante l’assunzione di indipendenza tra le caratteristiche, che può sembrare limitativa, il Naive Bayes si dimostra spesso molto efficace in scenari reali, fornendo una solida base per esplorare tecniche di machine learning più avanzate.
Probabilità Condizionata: Capiamola insieme
Immaginate di lanciare una moneta. La probabilità di ottenere testa o croce è del 50%.
Questo concetto è alla base della teoria della probabilità: il risultato di un evento è influenzato dal numero di possibili esiti.
Ora consideriamo un mazzo di carte. Se pescate una carta a caso, qual è la probabilità che sia una regina?
Dato che ci sono quattro regine in un mazzo di 52 carte, la probabilità di pescare una regina è di 1 su 13.

Ma cosa succede se sapete che la carta che avete pescato è picche?
In questo caso, stiamo considerando la probabilità condizionata, dove conosciamo già un evento (la carta è picche) e stiamo cercando di prevedere un altro evento (la carta è una regina).
Utilizzando l’equazione proposta da Thomas Bayes, possiamo calcolare la probabilità di pescare una regina dato che la carta è picche, prendendo in considerazione le probabilità individuali dei due eventi.

Questo semplice esempio illustra il concetto di probabilità condizionata e dimostra come il Classificatore Naive Bayes si basi su principi probabilistici per fare previsioni.
Applicazione Pratica del Naive Bayes Classifier: Un Esempio con il Dataset del Titanic
Preparazione del dataset
Ricordate tutti il tragico naufragio del Titanic. Sebbene sia stato oggetto di un celebre film, non possiamo dimenticare che si tratta di un evento realmente accaduto, con esiti tragici per molte persone coinvolte.
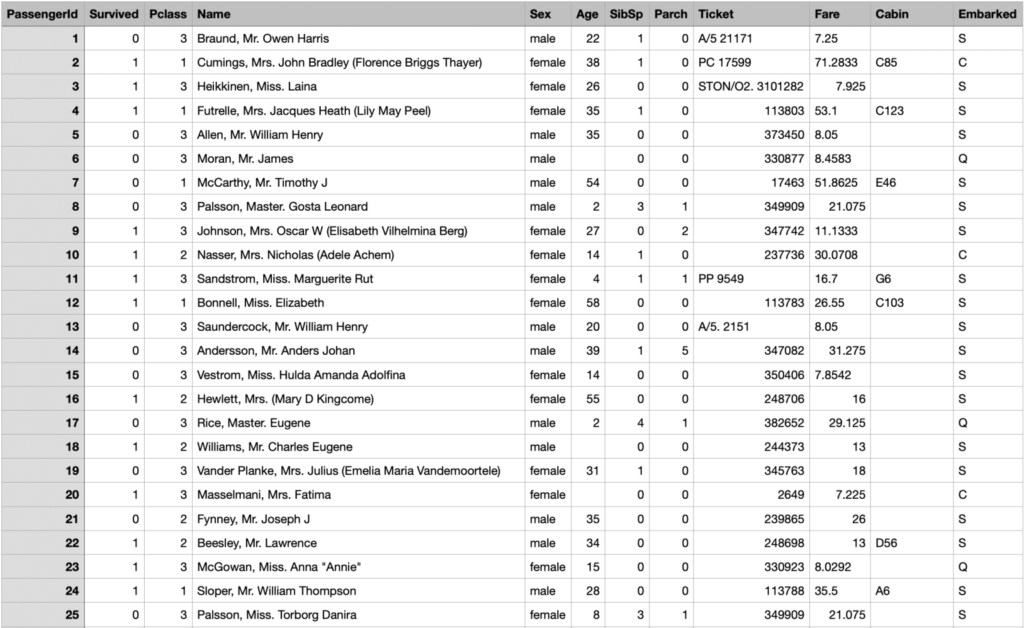
Su Kaggle.com disponiamo di un dataset relativo a questo disastro, contenente i nomi delle persone e diverse caratteristiche, come il sesso, la classe, l’età, il costo della cabina e così via.
Utilizzando queste informazioni e facendo uso teorema di Bayes miriamo a determinare se un passaggere con determinate caratteristiche fosse sopravissuto o meno.
Esplorazione e Pulizia dei Dati
Prima di tutto, bisogna esplorare i dati per identificare le caratteristiche rilevanti.
Ad esempio, il nome del passeggero e l’ ID del passeggero, non influiscono sulla probabilità di sopravvivenza, quindi vanno eliminate insieme ad altre variabili non rilevanti, semplificando il DataFrame.
Specifichiamo che:
axis='columns':
specifica che stiamo rimuovendo colonne, non righe. L’alternativa sarebbeaxis=0per rimuovere righeinplace=True:
indica che le modifiche devono essere applicate direttamente al DataFramedfesistente, anziché restituire una nuova copia con le colonne rimosse.
import pandas as pd
# Caricamento del dataset
df = pd.read_csv('titanic.csv')
# Rimozione delle colonne non rilevanti
df.drop(['PassengerId', 'Name', 'SibSp', 'Parch', 'Ticket', 'Cabin', 'Embarked'], axis='columns', inplace=True)Per preparare i dati per l’addestramento del modello di machine learning, è essenziale separare la variabile target (quella che vogliamo predire) dalle variabili indipendenti (quelle che utilizziamo per fare la predizione).
Nel caso del dataset del Titanic, la variabile target è Survived, che indica se un passeggero è sopravvissuto o no.
Ecco come effettuare questa separazione:
# Separazione della variabile target (Survived) dalle variabili indipendenti
target = df['Survived'] # Variabile target
inputs = df.drop('Survived', axis='columns') # Variabili indipendentiConversione delle Variabili Testuali
La colonna Sex conteneva valori testuali, bisogna convertirla in valori numerici usando l’encoding one-hot, essenziale per i modelli di machine learning.
dummies = pd.get_dummies(inputs.Sex)Concatenazione delle Variabili Dummy
Uniamo il DataFrame dummies al DataFrame inputs:
inputs = pd.concat([inputs, dummies], axis='columns')Gestione dei Valori NaN
Per identificare le colonne che presentano valori mancanti, si utilizza il seguente codice:
inputs.columns[inputs.isna().any()]Questo codice restituisce le colonne del dataframe ‘inputs’ che contengono almeno un valore mancante. Nel nostro dataset solamente la colonna Age presenta alcuni record con valori NaN.
Per garantire l’integrità e l’accuratezza dei dati, è essenziale affrontare questi valori mancanti in modo appropriato. Pertanto, si devono imputare i valori mancanti nella colonna ‘Age’ utilizzando la media dei valori non mancanti in quella stessa colonna. Questo è stato realizzato tramite il seguente codice:
inputs.Age = inputs.Age.fillna(inputs.Age.mean())Divisione del Dataset
Prima di addestrare il modello, si divide il dataset in campioni di addestramento e di test utilizzando il metodo train_test_split di scikit-learn, con una proporzione 80-20.
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(inputs, target, test_size=0.2)Quindi, la funzione train_test_split dividerà il dataset di input in due parti:
- X_train:
Contiene l’80% delle righe del dataframe inputs e corrisponde alle caratteristiche utilizzate per addestrare il modello. - X_test:
Contiene il 20% delle righe del dataframe inputs e corrisponde alle caratteristiche utilizzate per testare il modello. - y_train:
Contiene l’80% delle righe del dataframe target e corrisponde alle etichette di target associate alle righe in X_train. - y_test:
Contiene il 20% delle righe del dataframe target e corrisponde alle etichette di target associate alle righe in X_test.
Come possiamo confermare printando le varie lunghezze:
print(len(inputs)) # Output: 891
print(len(X_train)) # Output: 712
print(len(X_test)) # Output: 179
print(len(y_train)) # Output: 712
print(len(y_test)) # Output: 179Creazione e Addestramento del Modello Naive Bayes Classifier
Per questo caso d’uso si utilizza la classe GaussianNB di scikit-learn per creare il modello Naive Bayes, adatto quando i dati seguono una distribuzione normale (gaussiana).
from sklearn.naive_bayes import GaussianNB
model = GaussianNB()
model.fit(X_train, y_train)La funzione model.fit(X_train, y_train) prende in input due parametri:
- X_train:
Il set di caratteristiche di addestramento, che sono le variabili indipendenti. - y_train:
Il set di etichette di addestramento, che sono le variabili dipendenti o i target che il modello cercherà di predire.
Il metodo fit() addestra il modello utilizzando il set di addestramento fornito, adattando i parametri del modello alle caratteristiche e alle etichette fornite.
Ed ora è stata fatta la magia, alla fine di questo processo di addestramento del modello Naive Bayes Gaussiano, abbiamo un modello addestrato istruito sui dati di addestramento forniti, in grado di fare previsioni o classificare nuovi dati in base alla conoscenza acquisita durante l’addestramento.
Queste predizioni saranno basate sulla distribuzione delle caratteristiche dei dati di addestramento e sulle relazioni tra le caratteristiche e le etichette di addestramento.
Valutazione del Modello Naive Bayes Classifier
Dopo l’addestramento, si valuta il modello calcolando la sua accuratezza sul campione di test.
accuracy = model.score(X_test, y_test)
print(f'Accuracy: {accuracy * 100:.2f}%')Ecco cosa succede per valutare l’accuratezza:
- Input dei dati di test:
Il modello riceve come input le caratteristiche dei dati di test, rappresentati da X_test. Questi dati di test sono composti dalle stesse caratteristiche utilizzate durante l’addestramento, ma sono indipendenti dal set di dati di addestramento. - Previsione delle classi:
Utilizzando le caratteristiche fornite nel dataframe X_test, il modello esegue le sue previsioni sulle classi. Ad esempio, nel caso di classificazione binaria come nel dataset del Titanic, il modello prevederà se ciascun passeggero nel dataframe X_test è sopravvissuto (1) o no (0). - Confronto con i risultati effettivi:
Le previsioni fatte dal modello sono confrontate con le vere classi presenti nel dataframe y_test. Questo dataframe contiene le etichette reali (le vere classi) per i dati di test. - Calcolo dell’accuratezza:
L’accuratezza del modello è calcolata come la percentuale di previsioni corrette rispetto al totale delle previsioni fatte sul set di dati di test. In altre parole, il numero di previsioni corrette diviso per il numero totale di previsioni fatte.
Valutazione delle Prestazioni del Modello e Analisi delle Previsioni
Come test finale, ci focalizziamo sull’esame delle previsioni effettuate sui dati di test.
Il seguente codice stampa i primi 10 record del dataset di test X_test e le prime 10 etichette di target y_test, seguite dalle previsioni effettuate dal modello:
print(X_test[:10])
print(y_test[:10])
print(model.predict(X_test[:10]))Ecco cosa fa ciascuna riga di codice:
- print(X_test[:10]):
Stampa i primi 10 record del dataset di test X_test, che rappresentano le caratteristiche utilizzate dal modello per fare previsioni. Queste caratteristiche includono le variabili indipendenti come la classe del biglietto, l’età, la tariffa del biglietto, e le variabili dummy create dalle variabili categoriche come il sesso. - print(y_test[:10]):
Stampa le prime 10 etichette di target y_test, che rappresentano le vere classi o risultati che il nostro modello dovrebbe predire. In questo caso, le etichette di target indicano se il passeggero è sopravvissuto (1) o no (0). - print(model.predict(X_test[:10])):
Stampa le previsioni effettuate dal modello sui primi 10 record del dataset di test X_test. Queste previsioni sono generate applicando il modello addestrato ai dati di test e determinano se il modello classifica correttamente i passeggeri come sopravvissuti o non sopravvissuti.
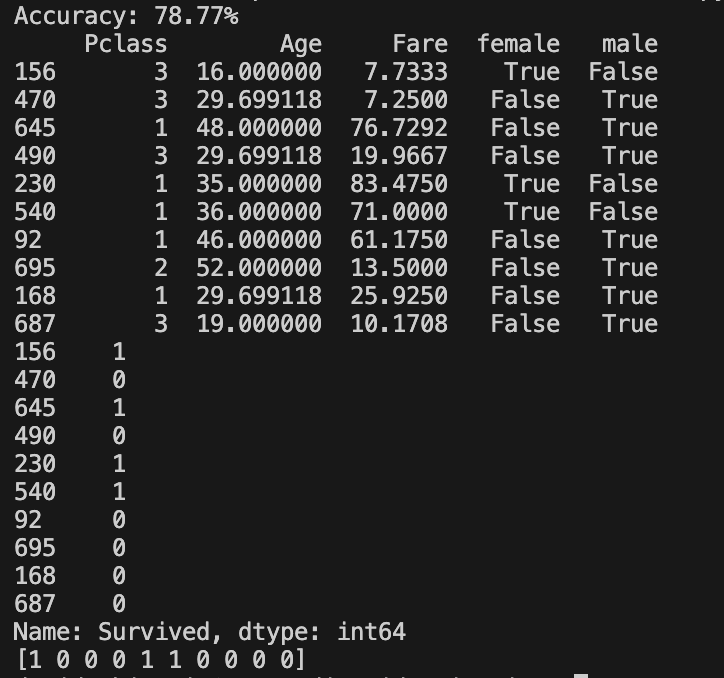
Come si può notare, il nostro modello sbaglia in alcune previsioni (del tutto normale dato che l’accuracy e di quasi 80% in questo caso).
Conclusioni
In conclusione, l’analisi e la modellazione del dataset del Titanic ci hanno fornito un’opportunità preziosa per esplorare i concetti fondamentali dell’apprendimento automatico e dell’analisi dei dati. Abbiamo iniziato con l’esplorazione e la pulizia dei dati, identificando e rimuovendo le variabili non rilevanti e affrontando i valori mancanti nella colonna dell’età. Successivamente, abbiamo preparato i dati per l’addestramento del modello, convertendo le variabili testuali in valori numerici e dividendo il dataset in campioni di addestramento e di test.
Utilizzando il modello Naive Bayes Gaussiano, abbiamo addestrato un classificatore per predire la sopravvivenza dei passeggeri del Titanic in base alle loro caratteristiche individuali. Abbiamo esaminato l’accuratezza del modello sui dati di test e utilizzato la funzione predict_proba per esplorare le probabilità predittive associate alle previsioni del modello.
Tuttavia, esistono diverse strategie che potremmo adottare per migliorare ulteriormente le prestazioni del nostro modello:
- Ingegneria delle Caratteristiche:
Potremmo esplorare ulteriori caratteristiche o creare nuove feature derivate dalle informazioni esistenti. Ad esempio, potremmo creare una nuova feature basata sulla dimensione della famiglia (somma di SibSp e Parch) o sull’età del passeggero. - Selezione delle Variabili:
Potremmo esaminare più approfonditamente l’importanza delle variabili nel modello e selezionare solo quelle più informative. Tecniche come l’analisi univariata e la feature importance possono aiutarci a identificare le variabili più predittive. - Tuning degli Iperparametri:
Potremmo sperimentare con diversi valori per gli iperparametri del modello per trovare la combinazione ottimale che massimizza le prestazioni del modello. Ad esempio, potremmo esplorare diverse opzioni per il parametro di smoothing nel Naive Bayes Gaussiano. - Utilizzo di Modelli Complessi:
Potremmo esplorare l’utilizzo di modelli più complessi e sofisticati, come alberi decisionali, foreste casuali o modelli di boosting, per catturare relazioni più complesse nei dati. - Valutazione Incrociata:
Potremmo utilizzare tecniche di valutazione incrociata per valutare le prestazioni del modello in modo più robusto e ridurre il rischio di overfitting.
Implementando queste strategie, potremmo sviluppare un modello più accurato e generalizzabile che fornisce previsioni più affidabili sulla sopravvivenza dei passeggeri del Titanic.




